Liebe Freunde,
ich habe versucht, im laufenden Betrieb CLBOSS von Version 0.10 auf 0.12 upzugraden. Seitdem stellt sich Raspine quer und will nicht mehr arbeiten.
![]()
Liebe Freunde,
ich habe versucht, im laufenden Betrieb CLBOSS von Version 0.10 auf 0.12 upzugraden. Seitdem stellt sich Raspine quer und will nicht mehr arbeiten.
![]()
Das hatte ich leider auch. Ich habe es ohne die SD zu flashen nicht wieder hinbekomme. Es war auch egal ob c-lightning im Menu deaktiviert u. wieder aktiviert habe. Debug war für mich auch nicht aufschlussreich. Letztendlich hat bei mir nur geholfen, v1. 7.2 neu auf die SD zu bringen.
Drücke die Daumen das Du es hinbeommst
Danke @SirSir21, haben es die Kanäle und Einlagen überlebt? Und bist Du dann auf CLBOSS 0.10 zurückgekehrt oder bist Du auf 0.12 geblieben?
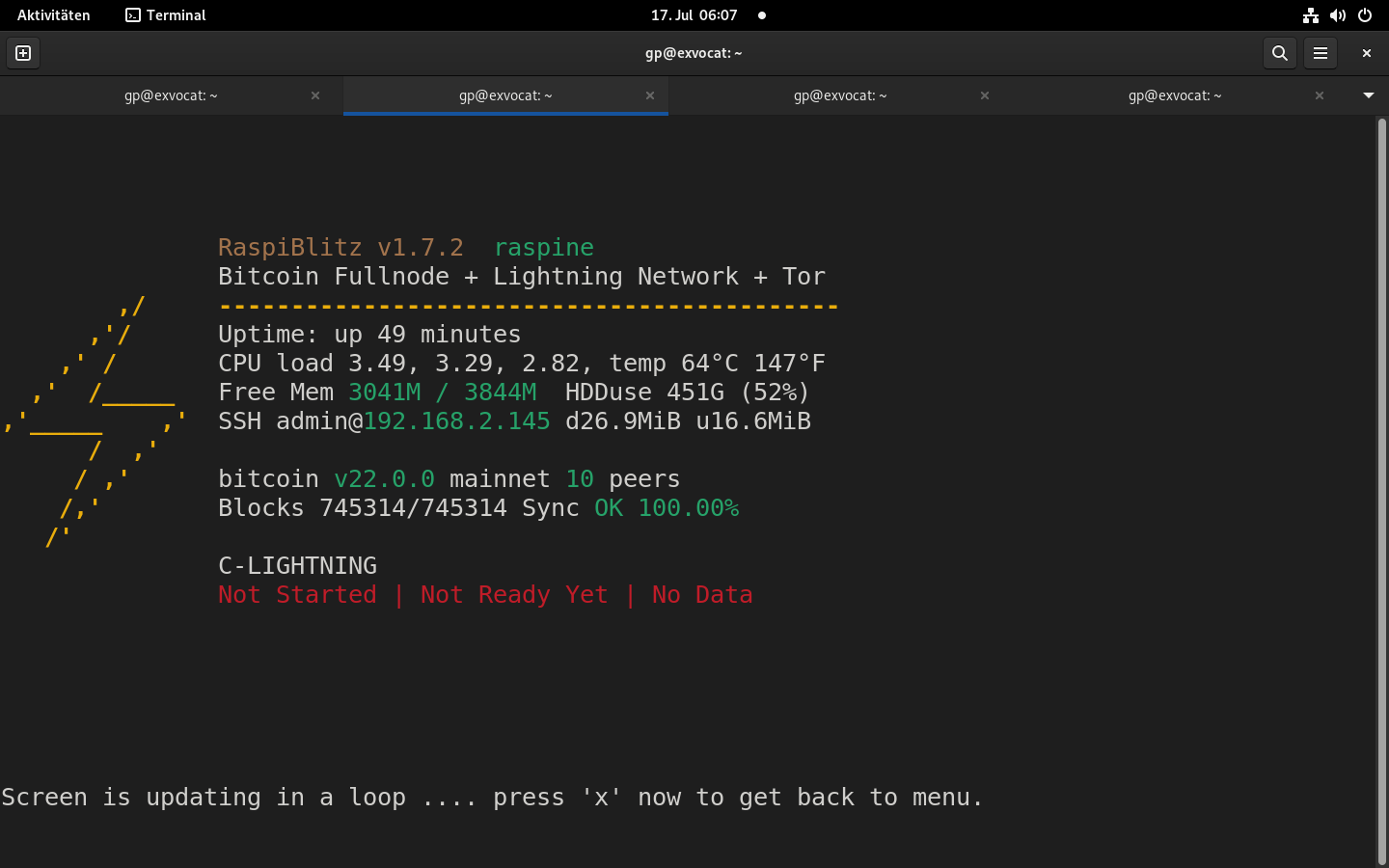
Bei mir ist im cl-log noch ziemlich viel los. Deshalb vermute ich, daß es noch läuft und nur der Kontakt zur Raspi-Oberfläche irgendwie gestört ist…
Im Zweifel kannst du immer via ssh unter Backup ein vollständiges CL-Backup erstellen, das du nach einem Neuaufsetzen inklusive frischer SSD jederzeit wieder einspielen kannst. Inklusive laufender Channel. Musste ich leider im Selbsttest ausprobieren ![]()
Hat das clboss upgrade denn problemlos funktioniert? Hast du bereit cln 0.11 am laufen? Dann muss eine extra setting in die conf geschrieben werden.
Ansonsten: clboss deaktivieren und vorher in der conf eventuelle Einträge auskommentieren. Ansonsten fällt mir weiter auch nichts außer dem Reflash ein (natürlich erstmal mit vestehender Platte als „Upgrade“)
Vielleicht bin ich nur zu ungeduldig. Im Hintergrund scheint noch irgendein versteckter DEBUG-Zauber zu laufen. In der (nicht mehr über das Menü erreichbaren) cl.log scheint ein kompletter „Rescan“ der gesamten Zeitstempelkette (vulgo: Blockchain) zu laufen, Die Einträge lauten immer
DEBUG lightningd: Adding block n ...
Gegenwärtig ist er um die 430.000. Da warte ich erst mal ab, bis er durch ist. Die REPAIR | REPAIR-CL | BACKUP -Lösung habe ich auch schon gefunden
Hast du bereit cln 0.11 am laufen?
Nein, ich bin direkt aus 0.10 vom 10m-Turm gesprungen. Hochmuth kömmt vor dem Fall.
![]()
Liebe Freunde,
während der rescan noch läuft, habe ich etwas herumgespielt. Frage ich mit check, wie es aussieht, er halte ich zur Antwort, alles sei OK.
$ check
RaspiBlitz Config: OK
RaspiBlitz Info: OK
$
Frage ich nach dem clboss-status, kommt eine Fehlermeldung:
$ lightning-cli clboss-status
lightning-cli: Connecting to 'lightning-rpc': No such file or directory
$
lighning-rpc – Was für eine Datei sucht sie, welche „Location“, welchen Besitzer und welche Dateirechte soll sie haben? Vielleicht löste eine einzige pipe schon das Problem. Bitte schaut einmal nach, wo sie bei Euch liegt usw.
Warum wartest du mit der Fummelei nicht erst einmal ab, bis der lightningd sich durch die Blockchain gewühlt hat (warum auch immer der das für nötig hält)?
Die Fehlermeldung vom lightning-cli interpretiere ich so, daß der lightningd aktuell keine RPC-Anfragen entgegen nimmt bzw. beantworten möchte, weil er ja mit etwas Wichtigem beschäftigt ist.
(Da ich auf meinem RaspiBlitz c-Lightning (noch) nicht einsetze, kann ich hier nicht genauer antworten. Ist lightning-cli eine Shellscript-Datei oder eine ausführbare Binary? Wenn Shellscript, dann einfach mal reinschauen und versuchen herauszufinden, wo evtl. der Fehlerzustand zustande kommt. Wäre jedenfalls mein Vorgehen, hätte ich deine Probleme. Ansonsten recherchieren, was zum Rescan der Blockchain geführt hat bzw. warum dieser nötig ist.
Ansonsten bin ich eher vorsichtig mit Updates von Teilkomponenten vom RaspiBlitz, wenn die nicht von selbst angeboten werden bzw. zwingende Sicherheitsprobleme diese fast erzwingen.)
Möglicherweise habe ich es selber angestoßen, als ich im Angesicht eines (zumndest teilweise) dysfunktionalen RaspiBlitzes auf alle Knöpfe gedrückt habe, die mir vor die Finger gekommen sind. Ich weiß selber, daß das horrible practice ist.
Die lightning-cli ist eine Binary, aber es gibt eine (für mich verstehbare) Manpage. Da steht:
lightning-cli sends commands to the lightning daemon.
und
–rpc-file=FILE Named pipe to use to talk to lightning daemon: default is lightning-rpc in the lightning directory.
Genau die fehlt bei mir. Ich habe die Zuversicht, daß sich aller Streß in Wohlgefallen auflöst, wenn ich diese Schnittstelle zur Verfügung stelle. Andernfalls bleibt mir immer noch das bereits verschiedentlich angeratene Reflashen. Ich vermute, Eigentümer der pipe sollte bitcoin sein. Brauchte ich noch die genauen Zugriffsrechte. Wenn Du, @Cricktor, oder irgend Jemand sonst sie hat, bitte teilt sie mir mit. Es sollte LND/CLN-unabhängig sein, denn mit lightningd müssen Alle reden, oder?
Ich denke, du solltest selbst wissen, daß diese Strategie eher ein Rezept für potentielles Desaster ist.
Wenn etwas nicht richtig zu funktionieren scheint, sollte man lieber nachforschen, was die Ursache sein könnte. Log-Dateien wären da für mich die erste Suchquelle, dann ein wenig Google-Fu oder Github-Fu der betreffenden Software, wenn man verdächtige Meldungen in den Logs gesehen hat.
Wenn man Logs selbst nicht interpretieren kann, dann kann man auch versuchen, mit den verdächtigen Log-Einträgen in Foren Hilfe zu suchen. Etwas Eigeninitiative zur Problemlösung wäre aber schon ganz nett und „foren-sozial“ und fühlt sich für einen selbst auch meist befriedigender an. Das ist jetzt keine konkrete Kritik von mir an dich, nicht missverstehen bitte.
Normalerweise sollte diese Named Pipe Datei durch den entsprechenden Aufruf des lightningd Daemons angelegt werden. Es kann aber sein, daß dein lightningd momentan, wie gesagt, mit etwas Wichtigerem beschäftigt ist, das dieser zunächst abschließen möchte, bevor er wieder RPC-Kommandos überhaupt lauschen möchte. Hier spekuliere ich aber, da bei mir LND läuft und dessen lncli kommuniziert über --rpcserver host:port mit dem LN Daemon.
An deiner Stelle würde ich abwarten, bis der lightningd mit dem fertig ist, woran dieser aktuell rumkaut. Wenn sich dann die Aktivität normalisiert hat, funktioniert entweder alles wieder normal oder du könntest einfach mal einen Neustart deines RaspiBlitz’ anstoßen und schauen, ob’s danach wieder normal läuft.
Zusätzlich würde ich mal diesem Hinweis nachgehen, was es damit auf sich hat. Möglicherweise hat sich ja etwas seit v0.10 derart geändert, daß essentielle conf-Einträge für neuere Versionen nötig sind.
Lieber @surenic,
die Frage verwirrt mich etwas. Brauche ich denn für clboss 0.12 cln (=c-lightning?) 0.11? Davon war damals, als Du mir den Tip und die Anleitung gegeben hattest, die ich jetzt (erst) vollständig und penibel befolgt habe, gar nicht die Rede gewesen. Oder habe ich da etwas überlesen? Ich war, meine ich, in der Standard-Konfiguration des Raspiblitz 1.7.2, als ich den „tapferen“ Schritt eines Teil-Upgrades (für clboss) gegangen bin. Stellt sich mir jetzt die Frage: „cln vor oder clboss`` zurück?“
Immerhin sagt die Raspine selbst: „c-lightning OK“. Und cl-boss ist namhaft im (aktuellen) log vertreten. Es fehlt meines Erachtens nur die Kommunikation zwischen meinen Tastatur-Eingaben und dem lightningd und der Raspine und dem Display. Ich würde doch gern testen, ob ich das nicht duch eine „handgemachte“ pipe zufriedenstellend lösen kann. „Zurück auf LOS“ kann ich dann immernoch, oder?
In der Anleitung von damals war CLN 0.11 (nicht CLBOSS) noch nicht draußen. Daher nun nochmal genau, um hier Mussverständnisse zu vermeiden:
Wenn du CLN 0.11 mit CLBOSS 0.12 vetreibst, ist ein Eintrag in der conf zwingend notwendig:
Da du RaspiBlitz 1.7.2 betreibst und vermutlich kein CLN Update gemacht hast, sollte der Punkt egal sein. Meine Expertise reicht an der Stelle hier für weitere Problemlösungshilfen leider nicht aus ![]()
Danke, @surenic, da bin ich schon mal beruhigt.
Mit welchen Zugriffsrechten und welchen bells and jingles muß ich meine lightning-rpc (oder so) denn nun ausstatten?
Also sah ich mich genötigt, den reflash-Weg zu gehen und durfte repetieren, warum ich ihn vermeiden wollte. Ob ich gleich eine Backup-Datei erstellt (und sie auch extern gespeichert) hatte, frug die Raspine gar nicht danach, sondern legte gleich (nach eigenem Gutdünken) los. Die Kanäle waren noch da, aber alle (preziösen) Anpassungen weg. Also fing ich ganz von vorne an: clboss 0.10 → 0.12. Das leitete (erwartungsgemäß) einen Rescan ein. Dann wendete ich meinen Uptime-Zauber an, dann den Fee-Report-Unit-Zauber. Dann „restaurierte" ich den Rebalance-Zauber durch symlink auf /home/bitcoin/cl-plugins-available/plugins/rebalance/rebalance.py. Als alles paletti schien, setzte ich noch in der cl.conf das Log-Level von debug auf info… und löste damit einen neuen Rescan aus. Der dauert bei mir immer etwa vier Tage.
Dazu hätte ich zwei Fragen:
Kann man das beschleunigen (etwa mit dem Electrum-Server)?
Ist mein rescan-Wert eigenlich in Ordnung? Er steht bei -1000. Ich dachte mir, er geht dann nur Tausend Blöcke zurück. Tatsächlich fängt er immer vom „Urschleim“ an.
Außerdem wurden mir in der langen Zwischenzeit drei von meinen fünef Kanälen gekündigt. ![]()
Immehin habe ich jetzt einen RaspiBlitz mit einem aktuellen clboss (der soll weniger „aggressiv“ swappen und/oder FundsMoven), einem „ordentlichen“ Uptime-Ausweis, einer korrekten Fee Report Unit und einem (mit-) lesbaren Log. Nun muß ich nur noch besser funden, Kanäle sammeln und dann will ich sehen, ob das schicke System noch etwas anderes kann, als meine Satoshis zu verbrennen. ![]()