Woche 16 – Das NVMe-Upgrade, viele Rückschläge und ein kleiner Triumph
Die Woche startet mit einem klaren Ziel: Ich möchte einen zusätzlichen ganzen Bitcoin in meine Node stecken.
Doch bevor ich das tue, steht noch ein anderes Vorhaben an – das Upgrade von SD-Karte + externer SSD auf eine M.2 NVMe.
Ich entscheide mich, das Upgrade zuerst durchzuführen. Sollte dabei etwas schiefgehen und ich den Recovery-Prozess starten müssen, würden ohnehin alle Kanäle geschlossen. Da wäre es wenig sinnvoll, vorher neue Kanäle zu öffnen, die dann direkt wieder verschwinden.
Die Hardware habe ich bereits letzte Woche besorgt und starte am Montagmorgen mit folgendem Plan:
-
Klonen der SD-Karte auf die NVMe
-
Vergrößern der relevanten Partitionen
-
Kopieren der Daten von der externen SSD auf die NVMe
-
Einbau der NVMe-Hardwareerweiterung in den Raspberry Pi
-
Wiederinbetriebnahme der Node mit NVMe
Jetzt wird’s etwas technischer – wer mag, darf diesen Teil gerne überspringen.
Montag – Das missglückte Upgrade
Gegen 12:30 Uhr beginne ich mit der Umsetzung. Ich fahre die Node herunter, verbinde die NVMe über einen USB-Adapter mit meinem Laptop und stecke die SD-Karte ein.
Das Klonen mit dd dauert länger als erwartet. Nach etwa 40 Minuten ist der 32GB-Klon fertig, die Partition angepasst, und ich schließe die externe SSD an.
Doch beim Kopieren der Daten mit rsync verabschiedet sich die NVMe regelmäßig nach wenigen hundert Megabyte – sie reagiert einfach nicht mehr. Nur ein Ab- und Anstecken hilft kurzfristig, aber nach kurzer Zeit tritt der Fehler erneut auf.
Das Klonen mit dd hatte problemlos funktioniert, also verstehe ich nicht, woran es liegt.
Das Upgrade ist also zunächst gescheitert.
Ich verbringe zwei Stunden mit Fehlersuche, bevor ich gegen 16:30 Uhr aufgebe und die Node wieder im alten Zustand mit SD-Karte + externer SSD starte.
Doch jetzt taucht ein neues Problem auf: Mein Bitcoin Core steckt in „pre-synchronizing“ fest.
Zuerst fürchte ich, die Blockchain-Daten könnten beschädigt sein.
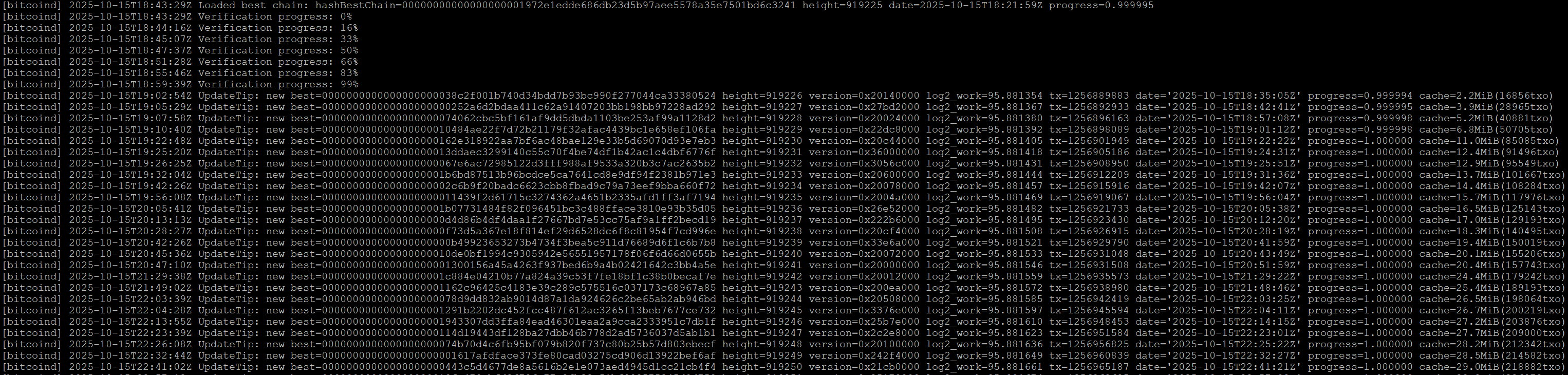
Nach einiger Zeit entdecke ich in den Logs jedoch den Hinweis: „Verification progress 16%“. Es hängt also nicht fest – es ist einfach nur unglaublich langsam.
Etwa 20 Minuten später ist die Node synchronisiert, aber ich bekomme keine Peers. Jeder Neustart führt erneut zu 15–20 Minuten „Verification“.
Als ich endlich ein paar Peers finde, dauert jeder Block mehrere Minuten. Das war früher nie so.
Erst spät am Abend läuft die Node wieder halbwegs normal.
Immerhin scheint nur Bitcoin Core betroffen zu sein, LND und die anderen Umbrel-Apps funktionieren weiterhin.
Dienstag – Neuer Plan, neue Hoffnung
Am Dienstag steht Plan B:
-
NVMe formatieren
-
SD-Karte erneut auf NVMe klonen
-
Node wieder mit SD-Karte + externer SSD starten
-
Partitionen auf der NVMe vergrößern
-
Blockchain über das lokale Netzwerk auf die NVMe kopieren (bei laufender Node)
-
Node herunterfahren
-
SSD mit Laptop verbinden und restliche Daten kopieren
-
NVMe-Hardwareerweiterung einbauen
-
Node mit NVMe starten
Ziel: kürzere Downtime, weil die Blockchain (der größte Datenteil) bereits im Hintergrund übertragen wird.
Nachmittags geht’s los. Das Klonen klappt erneut problemlos.
Doch das Problem mit dem langsamen „Verification progress“ bleibt bestehen. Wenigstens kann ich die Blockchain jetzt über das Netzwerk übertragen – leider nur über WLAN, da mein Laptop keinen RJ45-Anschluss hat.
Also läuft der Kopiervorgang die halbe Nacht, aber immerhin fehlerfrei.
Mittwoch – Erfolg und Frust zugleich
Mittwochmorgen will ich endlich fertig werden. Ich fahre die Node herunter, verbinde die SSD mit dem Laptop und starte den Kopiervorgang der restlichen Daten mit rsync.
Und wieder: die NVMe verabschiedet sich.
Ich verstehe es nicht – das Kopieren der Blockchain hat doch auch funktioniert!
Nach kurzer Verzweiflung mache ich Pause, und mit klarem Kopf fällt mir etwas auf:
Vielleicht ist das Problem gar nicht rsync, sondern die Geschwindigkeit.
Die Kopie von der SSD zur NVMe läuft deutlich schneller als das vorherige Klonen oder die WLAN-Übertragung.
Ich begrenze rsync also auf 30 MB/s – und siehe da: es funktioniert! Keine Fehler mehr, nur dauert alles ewig.
Gegen Nachmittag ist alles kopiert. Ich baue die NVMe in den Raspberry Pi ein, starte – und nichts passiert. Kein Netzwerk, keine Erkennung, keine Reaktion.
Ich teste die NVMe in einem anderen Pi, der sicher NVMe-bootfähig ist – ebenfalls nichts.
Das Upgrade ist erneut gescheitert.
Also wieder zurück zu SD-Karte + SSD.
Bitcoin Core braucht weiterhin 15–20 Minuten zum Start und lädt Blöcke extrem langsam.
Erst spät am Abend ist alles wieder online – und ich bin froh, dass kein Kanalpartner während der langen Offlinezeit geschlossen hat.
Ein neuer Plan muss her.
Donnerstag – Der Durchbruch
Am Donnerstag starte ich einen neuen Versuch:
Ich lösche die NVMe und spiele ein frisches Umbrel-Image auf. Dann teste ich sie in einem separaten Pi – und siehe da, sie funktioniert!
Also liegt es nicht an der NVMe.
Ich installiere Bitcoin Core, stoppe die App und lösche die App-Daten.
Dann kopiere ich mit rsync die Blockchain von meiner laufenden Node – dieses Mal über LAN, was alles deutlich schneller macht.
Nach etwa drei Stunden ist die Übertragung abgeschlossen und ich kopiere den Rest bei ausgeschalteter Node.
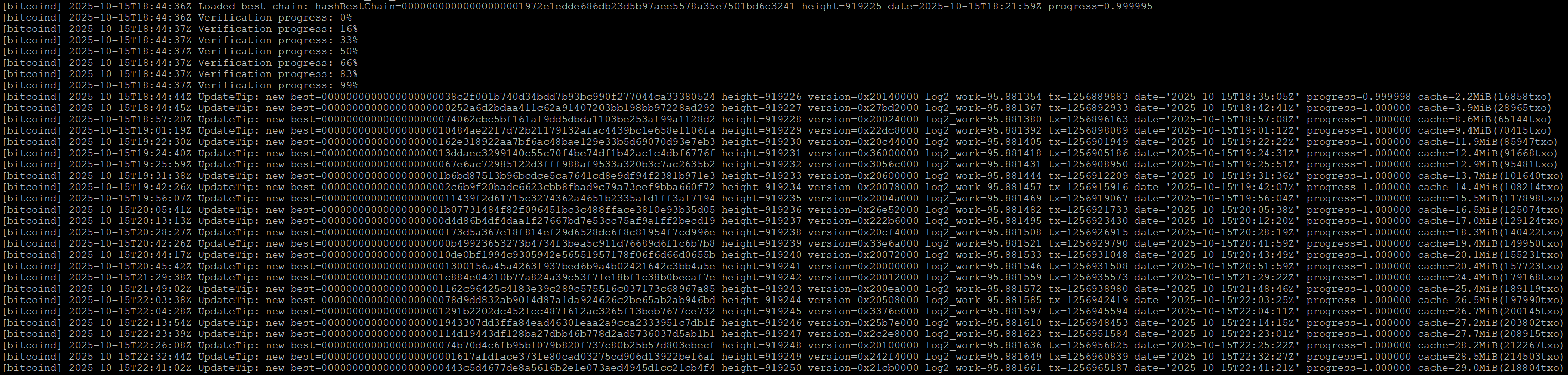
Ich starte Bitcoin Core – und es funktioniert!
Der Unterschied ist unglaublich:
Alte Node:
Neue Node:
Alt: ca. 17 Minuten „Verification progress“, 23 Minuen Synchronisation
Neu: etwa 2 Sekunden „Verification progress“, 8 Sekunden Synchronisation
10 Sekunden vs. 40 Minuten vom Start bis zur vollständigen Synchronisation. Ich bin begeistert und mache gleich weiter: auch Electrs und Mempool laufen nach der gleichen Methode perfekt.
Nun wage ich mich an den kritischen Teil: LND.
Ich erinnere mich noch an Sayo (Woche 3), der versehentlich zwei Instanzen seiner Node gleichzeitig online hatte – mit fatalen Folgen. Das will ich unbedingt vermeiden.
Mein Plan:
-
Installation aller verbleibenden Apps (inkl. LND)
-
Löschen der App-Daten
-
Deaktivieren aller Apps auf beiden Nodes
-
Kopieren der App-Daten von alt → neu
-
Aktivieren von LND, LNDg und LNbits auf der neuen Node
-
Wenn alles funktioniert: Deinstallation aller Lightning-Apps auf der alten Installation
Donnerstagabend ist es so weit. Ich führe alles durch, aktiviere LND – und Erfolg!
Die Node startet sofort, verbindet sich mit allen Kanalpartnern, Thunderhub und RTL funktionieren, LNbits ebenfalls.
Nur LNDg zickt: Passwort ungültig.
Ich teste das alte Passwort – funktioniert.
Ich beschließe, das später zu lösen, deinstalliere die Lightning-Apps auf der alten Installation und mache erst mal Pause.
Freitag – Feinschliff und Passwort-Abenteuer
Am nächsten Tag baue ich alles ordentlich ins Gehäuse ein und gehe das LNDg-Passwortproblem an.
Umbrel oder LNDg bieten keine Möglichkeit, das Passwort zu ändern.
Ich finde die SQLite-Datenbank und sehe den gehashten Passwortwert.
Also versuche ich, denselben Hash zu erzeugen – aber ohne Erfolg.
Die Hashfunktion scheint etwas mit Django zu tun zu haben, aber ich bekomme keinen identischen Hash hin.
Dann kommt mir eine Idee:
Ich erstelle ein Backup der LNDg-Daten, deinstalliere die App, installiere sie neu und logge mich mit dem neuen Umbrel-Passwort ein – funktioniert!
Ich kopiere den neuen Passwort-Hash aus der Datenbank, stelle das Backup mit den alten Einstellungen wieder her und ersetze dann nur den Hash.
App neu starten, Login testen – Erfolg!
Neues Passwort, alte Einstellungen. Perfekt.
Samstag – Alles läuft… fast
Alles funktioniert wieder – bis auf meine Bolt Card.
Sie will nicht, aber ich beschließe, das Thema auf nächste Woche zu verschieben.
Auch ein kleines Problem mit der Bitcoin-Core-App bleibt erst mal liegen.
Wichtig ist: Die Node läuft, stabil und schnell.
Leider bin ich durch die langen Offlinezeiten auf Lightning Terminal von Platz ~100 auf etwa Platz 1700 gefallen.
Das wird wohl etwas dauern, bis sich das erholt.
Deshalb verschiebe ich den geplanten Bitcoin-Zufluss auf nächste Woche.
Wenn der Rang wieder besser ist, werden auch gute Pool-Anfragen und Swap-Partner einfacher zu finden sein.
Der Bitcoin dafür ist jedenfalls schon bereit.
Die Antwort von cyberdyne.sh
Zum Schluss noch die Antwort von Silen, dem Betreiber von cyberdyne.sh.
Er bestätigt, dass er den Kanal tatsächlich wegen der positiven eingehenden Gebühren geschlossen hat.
Nicht, weil seine Node sie nicht versteht – sondern weil sein Rebalancing-Tool damit nicht umgehen kann.
Er habe dadurch zu viel für Rebalancing bezahlt und wollte mich eigentlich kontaktieren, fand aber keine Kontaktmöglichkeit.
Vor dem Schließen stellte er sicher, dass fast die gesamte Liquidität auf meiner Seite liegt – sehr fair!
Er ist grundsätzlich offen für einen neuen Kanal, bittet aber darum, dass ich positive eingehende Gebühren nicht über 25 ppm setze.
Das werde ich selbstverständlich berücksichtigen – beim nächsten Batch-Opening.
Ach ja, und während des ganzen Chaos hat Sally Acorn spontan einen 2M-Sats-Kanal zu mir geöffnet – da hatte ich wohl Glück, dass die Node gerade online war.
Fazit
Diese Woche war technisch anspruchsvoll, anstrengend und frustrierend – aber auch unglaublich lehrreich.
Ich habe viel über Umbrel, seine Verzeichnisstruktur und das Zusammenspiel der Apps gelernt.
Sollte ich irgendwann erneut migrieren, z. B. auf ein x86-System, weiß ich jetzt genau, wie ich vorgehen muss – und würde sicher deutlich schneller ans Ziel kommen.
Leider war ich diese Woche kein besonders guter Kanalpartner.
Durch die langen Offlinezeiten waren viele Kanäle unbenutzbar.
Falls jemand hier mitliest, der einen Kanal mit mir hat: Sorry dafür – ab jetzt sollte es wieder stabil laufen.
Mein Ziel, einen weiteren Bitcoin einzusetzen, habe ich nicht erreicht – nicht einmal begonnen.
Aber am Ende zählt: Das Upgrade hat funktioniert, und meine Node ist bereit für die nächsten Schritte.
Die Gesamtkapazität der Node am Ende der Woche beträgt ca. 2,52 BTC in 68 Kanälen.