Danke für Deine Gedanken und die Möglichkeit, mich mit Dir darüber auszutauschen.
Was wäre Dir lieber gewesen?
Ich kenne zwei Ansätze aus den Naturwissenschaften:
das Schrotschussprinzip: zu deutsch, ich probiere etwas aus und schaue, was passiert
ich entwickle ein Modell bzw. eine Theorie (auch aufbauend auf 1) und unterziehe sie Experimenten, um die Verlässlichkeit und Gültigkeit des Modells zu erkunden.
Nach meinem Verständnis entspringt das Bitcoin Power Law (BPL) dem 1. Prinzip und muss sich gerade entsprechend des 2. Prinzips bewähren. Was ist daran falsch? Bzw. was brauchst Du?
„Kann man frei wählen.“ So ich die statistischen Verfahren richtig in Erinnerung habe, geht es doch er um ein Optimierungsproblem, das gelöst wird. Natürlich mit dem Ergebnis, die Funktion zu finden, die den Verlauf des Bitcoin Kurses am besten beschreibt.
Was mich nicht euphorisch, aber doch aufmerksam werden lässt, ist die Tatsache, dass die Parameter des BPL sich seit einigen Jahren nicht mehr verändern. (Natürlich darf man bei der Anwendung des BPL nicht seine Grenzen außer acht lassen.)
Natürlich nicht. Wir haben nicht alle das Glück auf eine Jahrhunderte alte Wissenschaft wie die Physik zurückgreifen zu können. Doch auch die Physik hat einmal klein angefangen und lange gebraucht, bis sie Modelle hervorbrachte, die kaum noch in Frage gestellt werden. Die Erforschung der Bitcoin-Wirtschaft ist eben erst am Anfang. Ob das BPL von Dauer trägt, keine Ahnung. Doch solange es nicht bricht, was ist dagegen einzuwenden?
Das gilt für viele Modelle, trotzdem finden sie Anwendung.
Ich habe es so verstanden, dass das BPL zwar einen Erwartungswert ausgibt, es aber im wesentlichen darum ginge,
nie tiefer als der Worst Case zu fallen und
die Kurse in etwa 50% der Zeit oberhalb der Linie liegen und die restliche Zeit darunter.
Damit kann ich arbeiten.
Fair enough. M.E. ist das BPL dafür aber auch gar nicht gedacht. Dafür gibt es doch die Varianztrends von Bitcoin. Vielleicht schafft es mal ein schlauer Mathematiker, beides zu verbinden
Genau. Auch hier würde ich wieder sagen: das gilt für jedes Modell. Ihr Physiker seid nur verwöhnt, dass Eure Basics Naturkonstanten sind. Dieses Glück können die meisten anderen wissenschaftlichen Disziplinen noch nicht genießen. Das heißt doch aber nicht, die Augen zu verschließen und es nicht wenigstens zu versuchen. Oder?
Alles nicht, aber VIELLEICHT den Worst Case für den Bitcoin Preis. Das würde mir schon ausreichen. Solltest Du hierzu begründbare Bedenken haben, wäre ich sehr daran interessiert.
An welche Aussagen denkst Du? Mir leistet das Modell bisher gute Dienste (ohne Haus und Hof darauf setzen zu wollen.)
Du kennst doch das Spiel. Ich erstelle mit der einen Hälfte der Daten ein Modell und evaluiere anhand der zweiten Hälfte seine Gültigkeit und Verlässlichkeit. Dasselbe gilt für das BPL. Natürlich gibt das noch keine Garantie, dass das Modell auch in alle Ewigkeit trägt. Aber bis dahin gilt:
Wo ist mein Denkfehler?
Und damit es nicht untergeht, wiederhole ich noch einmal meine brennendste Bitte hinsichtlich der Worst Case Betrachtung:
Solltest Du hierzu begründbare Bedenken haben, wäre ich sehr daran interessiert.
Du tust die ganze Zeit so, als hättest du wirklich ein fundamentales Interesse daran, ob so ein Modell „richtig“ sein kann.
Aber hast du folgendes mal gemacht?
Und meinst du ernsthaft, ein Modell mit wenigen Parametern enthält die gesamte Zukunft unserer Welt, inkl. allen technologischen Durchbrüchen, Inflation, Krisen / Black Swan Events etc.? Von alledem hängen nämlich auch Bitcoin Kurs-Minima ab.
Eigentlich fehlt nur noch, dass @Bontii hier auftaucht und mir erklärt, dass man das Bitcoin Power Law sowie das Schicksal der Welt aus Fraktalen und Entropietaschen herleiten kann.
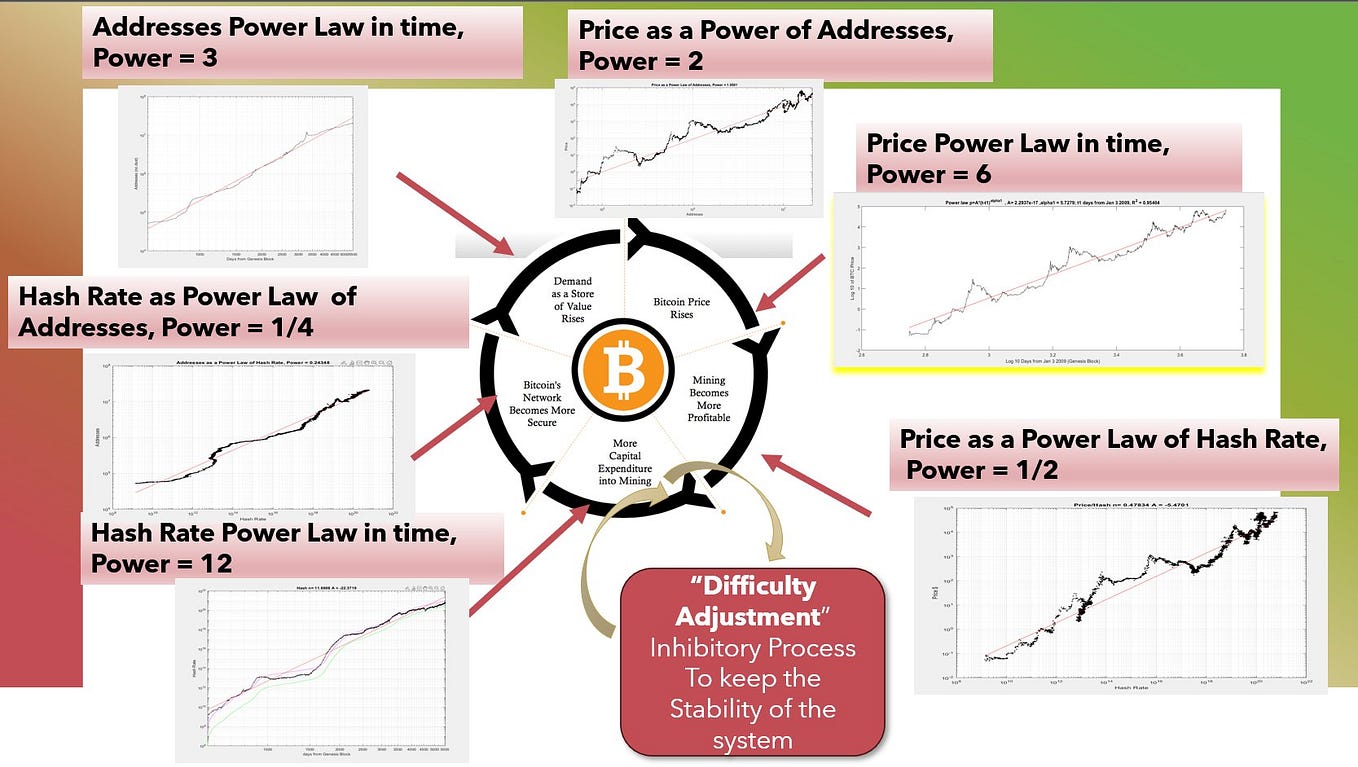
Die Anzahl der Benutzer (~Adressen) im Netzwerk wächst mit ca. t^3. Der Wert eines sozialen Netzwerkes ist proportional zum Quadrat der Anzahl der Benutzer (Metcalfe‘s Law). Daher folgt der Wert/Preis dem Trend t^3^2=t^6. Auch bekannt als Bitcoin Power Law.
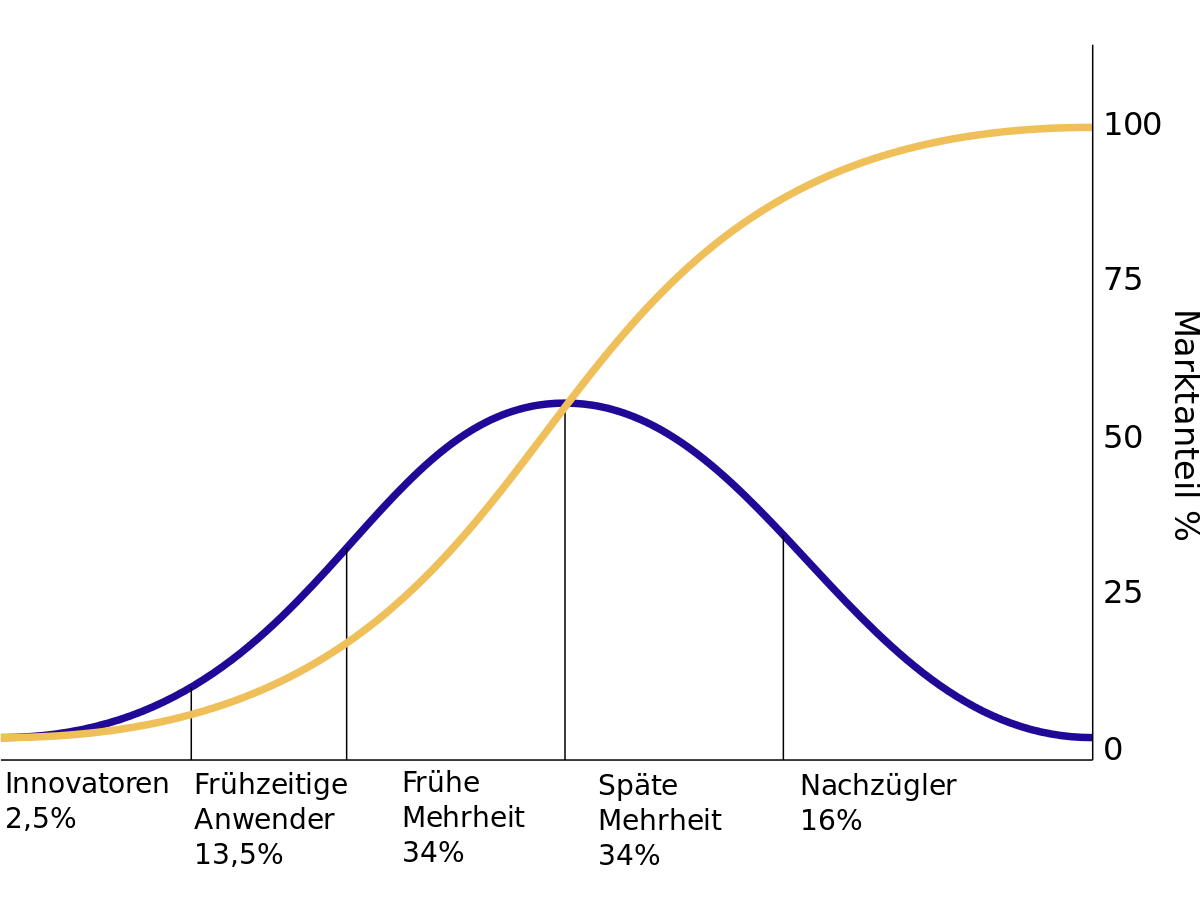
Mein Verständnis ist, dass wir noch nicht in der Massenadoption von Bitcoin sind. Es nutzen noch nicht annährend so viele Leute Bitcoin, wie z.B. ein Mobiltelefon nutzen. Die Überlegung wäre, dass wir uns in der „S“ Adoptionskurve daher noch im „unteren Bogen“ befinden. Am Anfang der der frühen Mehrheit:
Solange der Bogen noch nicht in eine Gerade übergegangen ist, scheint das BPL sinnvolle Vorhersagen zu treffen, läuft dann aber nach oben aus der Vorhersage.
Da wir nicht wissen wann das BPL den Bereich der Aussagekräftigkeit verläßt, finde ich es nur teilweise hilfreich.
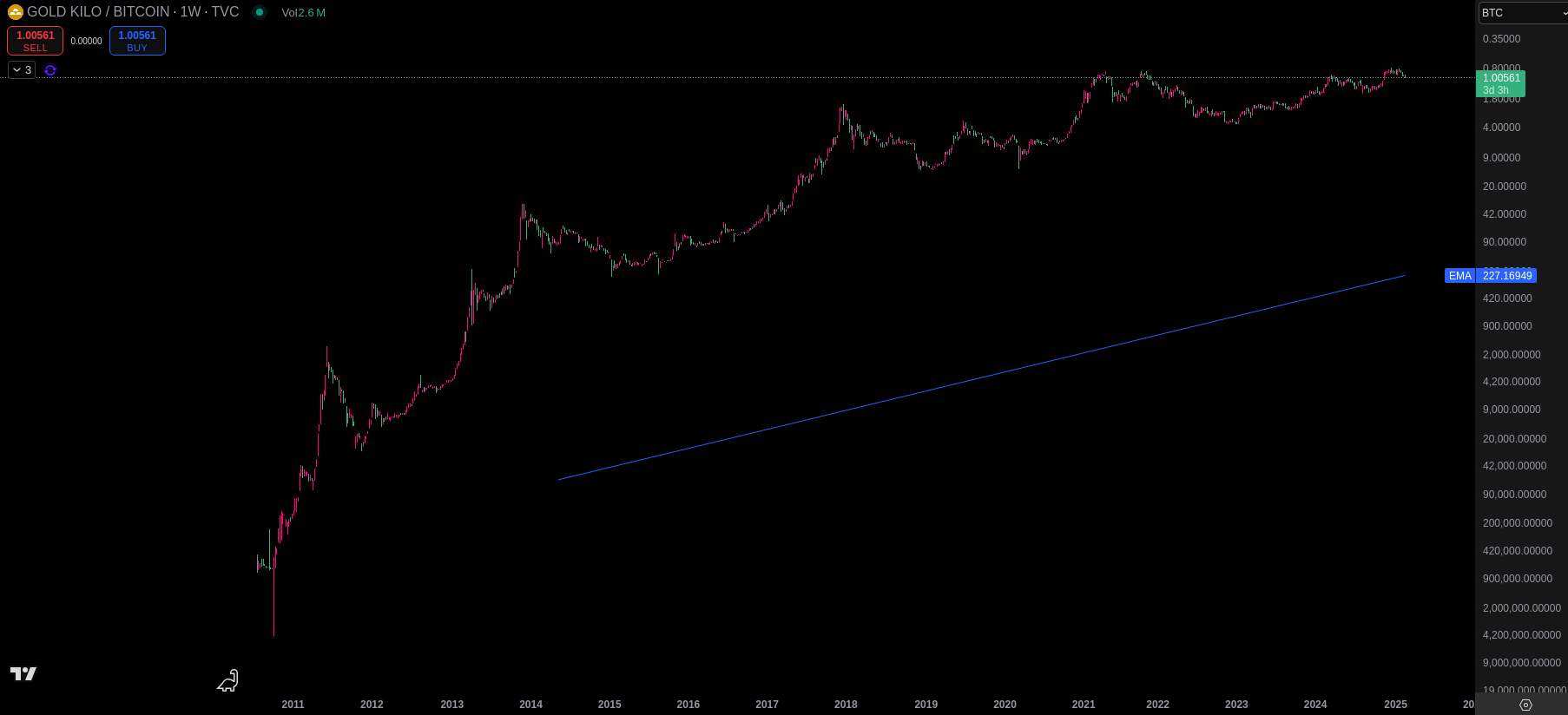
Man kann allerdings z.B. mit Hilfe vom Gold / Bitcoin Chart einige zusätzliche Dinge erkennen:
Der EMA 200 Wochen ist eine Gerade und hat ähnliche Eigenschaften, wie die Geraden im Log / Log Scale des BPL. Solange der EMA200 eine Gerade bleibt würde sich das BPL verhalten wie bisher.
Bei einem „Knick“ nach oben würden wir in die steile Phase der Adoption eintreten.
Ich habe nichts dagegen, wenn Andere versuchen Modelle aufzustellen und damit versuchen ihre Umgebung oder ihr Weltbild zu beschrieben. Ich persönlich verstehe nur nicht den Hype um genau dieses Modell, eines von vielen.
Ich vermute, dass es aus der Faszination kommt, die die Mathematik drumherurm gesponnen hat. Die Mathematik selber kann dabei natürlich auch spannend sein, aber in diesem Modell werden aus physikalischer Sicht absolute Basics verwendet, die schon in den Einführungswochen eines Physikstudiums durchgerechnet werden, zumindest war das bei mir so. Das ist vielleicht der Grund, warum das Modell Physiker nicht vom Hocker haut.
Außerdem solltest du verstehen, was Modelle für eine Aussagekraft haben können:
Die Physik versuch die Realität in ihren Grundsätzen zu verstehen. Früher hieß diese Disziplin deswegen Naturphilosophie und erst mit der mathematischen Systematik beginnend mit Keppler oder Newton bekam das Fach den Namen Physik.
Grundsätzlich hast du recht, die Physiker stellen sich ein Modell auf, prüfen dieses Modell in der Wirklichkeit und schauen dann, ob die Vorhersagen des Modells richtig sind oder ob sie das Modell als „Falsch“ verwerfen müssen. Falsch ist hier vielleicht nicht das richtige Wort weil auch falsche Modelle Erkenntnisgewinn bedeuten und diese Modelle auch leicht abgeändert werden können um so vielleicht richtigere Ergebnisse liefern.
Was ich damit sagen will ist: Modelle haben ein Spektrum der Richtigkeit bzw. Grenzen, in denen sie ausreichend gut gültig sind und dementsprechend auch Bereiche, in denen sie zu deutlich von der Realität abweichen. Für jedes Modell ist es also absolut entscheidend, diese Abweichungen der Realität zu kennen und mit Fehlerangaben zu versehen um zu erkennen, ob man das Modell anwenden kann oder ob man lieber ein anderes Modell wählen sollte. Modelle ohne diese Abweichungsangaben bzw Fehlerbalken können natürlich theoretisch genauso interessant sein, aber sie sollten dementsprechend nicht überbewertet werden, gerade weil eine Mathematik darin dann eine Genauigkeit vortäuscht, die physikalisch nicht gegeben ist.
Diese Aussagen über Modelle sind allgemeingültig, also für alle individuellen Modelle anwendbar bzw. die generellen Eigenschaften eines Modelles sollten immer berücksichtigt werden. Und diese generellen Modelleigenschaften lernt man in der Physik, aber die Theorie dahinter hat natürlich auch für alle anderen Wissenschaftsbereiche, die Modele aufstellen ihre Gültigkeit. Auch Geisteswissenschaftler stellen immer wieder Modelle auf und wenn sie sich nicht an die Modelltheorie halten, dann können sie eben das Problem bekommen, dass ihre Modelle zwar schön aussehen, aber nichts mit der Realität zu tun haben.
Jeder Roman ist z.B. ein eigenes Modell und wenn die Protagonisten darin eben zaubern können oder sonstwie Magie ausüben, dann ist das zwar für das Modell richtig, aber nicht für die Realität.
Was Physiker nun generell machen ist herauszufinden, was man über die Zukunft in Modellen vorhersagen kann. Dazu ist es aber absolut notwendig jedwede Störquellen auszuschließen um die betrachtete Eigenschaft messen zu können. Wenn du messen willst, wie schnell ein Ball einen Brunnen herunter fällt, dann ist es ungünstig, wenn der Ball ständig zwischen den Wänden hin und her abprallt. Für die Fallgeschwindigkeit muss diese Störquelle abgeschafft werden. Umso genauer man aber messen will, desto komplizierter wird es die Störquellen abzuschaffen. Irgendwann auf einer sehr kleinen Skala sind z.B. schon alleine die Stöße des Balls mit den Luftmolekülen so störend, dass man das Experiment im Vakuum durchführen muss.
Das Prinzip gilt für alle Experimente, genauso wie im Cern die Teilchen auf definierten Bahnen gehalten werden um überhaupt vergleichbare Aussagen zu bekommen.
Mal als Anekdote: Früher gab es im Teichenbeschleuniger vom Cern exakt einmal in der Stunde riesige Abweichungen von allen Messungen. Irgendwann sind die Physiker darauf gekommen, dass diese Abweichungen mit dem Fahrplan des TGV korreliert. Also immer wenn der Schnellzug über das Gelände gefahren ist gab es ein Magnetfeld, dass jegliche Messungen der Teilchen beeinflusst hat, sodass diese Messungen unbrauchbar waren.
Für die Modelltheorie bedeutet es, dass dieser Zug nicht im Modell der Physiker vorgesehen war. Trotzdem hat der Zug in der Realität einen Einfluss auf die wirklichen Vorgänge gehabt und die Messungen waren falsch, also nicht der Theorie bzw. dem Modell entsprechend. Bei so einem Modellversagen gibt es mehrere Möglichkeiten, wie man weiter vorgeht:
Entweder man versucht die Messung weiter zu isolieren und die Störquellen auszuschließen um zum Kern der messbaren Eigenschaft zu kommen oder man versucht die Störquellen mit in das Modell aufzunehen und beschreibbar zu machen. Beide Wege führen dazu, dass das neue Modell wahrscheinlicher die Realität abbildet.
Worauf ich mit diesen Beispielen hinaus will ist, dass jedem Physiker bewusst sein muss, wo die Anwendungsgebiete eines Modells liegen und wo man das Modell nicht verwenden sollte. Auf größerer Ebene kannst du z.B. für den normalen Alltag problemlos die Newtonsche Physik anwenden, die aber für andere Anwendungen wie PC oder Satelliten zu große Abweichungen von der Realität bedeuten würde. Dann muss man zu den genaueren aber komplizierteren Quantenmechanik oder Relativistik gehen.
Und mit dieser Vorrede über generelle Modelle kommen ich wieder zurück zu dem beschriebenem Modell. Im Sinne der Physik weist das Modell eben gravierende Mängel auf, was die Vorhersagbarkeit betrifft. Wie im vorherigen Post beschrieben macht es keine Aussage über die Schwankungen und gibt auch keine Fehlerbereiche an. Und die Aussagen über die Zukunft sind hochgradig abhängig von den Störquellen. Das Bitcoinnetzwerk ist eben anders als in der Physik nicht isoliert sondern hochgradig interaktiv in der Welt.
Wie gesagt, die Aussagen über die Zukunft in dem Modell sind einfache Trendfortführungen der Vergangenheit ohne jegliche Störquellen mit zu berücksichtigen, das gibt das Modell einfach nicht her. Die Tatsache, dass da mit viel Mathematik gerechnet wird übertüncht den Fakt, dass man genauso gut handgemalt eine Linie weiterziehen könnte, die exakt die gleiche Aussagekraft über den Preis der Zukunft hat wie das Modell es ausspuckt. Beide Linien reagieren nicht auf etwaige Störungen in der Zukunft, die aber mit absoluter Sicherheit auftreten.
Das Modell hat also nichts mit einem physikalischem isolierten System zu tun, das Modell ist ehr wie ein Roman zu sehen. Es soll die Wirklichkeit in gewisser weise Abbilden aber wegen den Störquellen ist es sehr wahrscheinlich, dass es in Zukunft nicht mehr die Realität zeigen wird. Die Frage für mich ist deswegen nicht ob es brechen wird, sondern wann.
Deswegen sage ich: Die Tatsache, dass da viel Mathematik drinsteckt bedeutet nicht, dass die Aussagekraft des Modells größer wird. Es ist ein Modell wie viele andere Modelle auch, die man aufstellen kann wie die Komplexe Welt den Bitcoinpreis verändert.
Die Gemeinsamkeit all der verschiedenen Modelle ist bei exponentielles Wachstum das e. Und bei polynomialem Wachstum in Verbindung mit einem Regressionsanpassung bin ich eh skeptisch. Wenn man z.B. Taylorreihen verstanden hat, dann weiß man, dass man nur die Polynomgrade erhöhen muss um die festen Werte (historische Preisdaten) mit der zu fittenden analytischen Kurve zu treffen. Auch wenn dieses Polynom dann alle historischen Werte exakt treffen kann ist die Vorhersage für neue Werte dann meistens miserabel weil das zugrunde liegende reale Wachstumsgesetz, das hier abgebildet werden soll, doch ehr exponentielles Wachstum ist (also eingeschlossen Logistisches Wachstum, Gauskurven oder andere Beschränkungen).
Man sollte also nicht zu viel in das konkrete Modell hineininterpretieren, was nicht da ist. Vorallem sollte man nicht den Fehler machen und aus dem Modell schlussfolgern, dass die getroffenen Annahmen für das Modell bestätigt werden, dass kann ein Modell definitionsgemäß nicht.
Stell dir mal das Modell als eine Backbox vor: Du steckst vorne Informationen rein und hinten kommen Informationen wieder raus. Alles was du vorne an Informationen hineinsteckst muss dir bekannt sein, sonst könntest du diese Informationen nicht in das Modell stecken. Wenn du hinten also die bekannten Informationen wieder herausbekommst, dann bist du bezüglich der Eingangsinformation nicht schlauer geworden, diese Information kennst du ja schon. Was du dadurch lernst ist die Funktionsweise der Blackbox, also wie dein Modell die Information überhaupt verarbeitet. In unserem Fall haben wir das Modell aber selber aufgestellt und wir wissen, was darin abläuft. Der Informationsgewinn ist also abgesehen davon, dass das Modell mathematisch funktioniert sehr begrenzt.
Wenn du mit dem Modell also den Preis der Zukunft vorhersagen willst ist das genauso wie wenn du dem Modell die Frage stellst: Wo ist der Preis in 3 Tagen wenn in 3 Tagen der Preis auf dem Wert 100000€ steht? Was du eben immer im Hinterkopf behalten solltest ist, dass jegliche Beantwortung des zukünftigen Preises die Bedingung hat: Wenn es so weiter geht, dann ist der Preis am Tag X f(x). Jetzt kannst du exakten Werte verwässern aber dafür auch die Aussagekraft verringern: Wenn es so weiter geht, dann ist der Preis am Tag X nicht kleiner als f(x). In jedem Fall bleibt die Bedingung: Wenn das so weiter geht.
Ich hoffe du verstehst damit, warum diese Grundaussage des Modells keinen Physiker vom Hocker reist. Genau deswegen die Frage: Was fasziniert dich an dem Modell so sehr? Die Preisvorhersage kann es meiner Meinung nach nicht sein, denn darüber macht es wie gesagt keine verlässliche Aussage.
Ist es das generelle Wachstumsgesetzt, das sich auch auf ähnliche Wachstumsarten anwenden lässt? Ich meine dieses Modell ist ja vergleichbar mit dem Mooreschem Gesetz. Aber auch das Modell ist lediglich eine Trendkurve: Mit der Bedingung: Wenn es so weiter geht, dann geht es so weiter.
Oder ist es die Verbindung zur Kardaschow-Skala, die ja ersteinmal nur 3 diskrete Zivilisationsgrade definiert und mit so einer Trendlinie auch die Fortführung zwischen den diskreten Werten für die Zeitentwicklung abgeschätzt werden kann?
Viel interessanter wird es natürlich, wenn man die Skaleninvarianz betrachtet. Das bedeutet, dass die genaue Kurve unabhängig der Skala immer ungefär gleich aussieht. Also ob man die Kurve für eine Stunde, einen Tag, einen Monat oder ein Jahr betrachtet, all diese Kurven sehen ungefär gleich aus.
Aber haben wir das wirklich mit dem Modell? Das Modell macht doch überhaupt keine Aussage über die Schwankungen. Ja eine Exponentialfunktion ist auch skaleninvariant, genau wie eine X^Y Funktion. Das ist aber eine Eigenschaft der benutzten Funktion und keine Eigenschaft, die das Modell vorhersagt.
Können wir mit dem Modell die Phasenübergänge betrachten? Eine einfache analytische Funktion hat keine verschiedenen Phasen, die wir untersuchen könnten und bei denen die Skaleninvarianz eine Rolle spielen könnte.
Wie gesagt, die Welt zu analysieren ist ein spannendes Thema, aber ich verstehe den Hype um dieses spezielle Modell einfach nicht, wo es doch relativ gleichwertig zu vielen anderen Modellen ist, vorallem was die Aussagekraft bzw. dem Erkenntnisgewinn betrifft. Dass Bitcoin noch eine gute Zukunft haben wird weiß ich auch durch viele andere Betrachtungen und Modellen, vorallem durch die Eigenschaften von Bitcoin selber. Und einen Trend kann ich mir auch ausmalen, wenn ich mir die Vergangenheitswerte anschaue und beliebige Kurven da durchzeichne. Auch die erhaltenen Konstanten des Fits haben für mich noch keine wirkliche Aussagekraft, da sie für jedes betrachtete Wachstum eben unterschiedlich sind und sich auch mit jedem neuen Fit verändern werden, wenn mehr historische Daten da sind, gerade weil die Störeffekte von außen nicht im Modell berücksichtigt werden und somit immerwährend auf die Fit-Parameter einwirken werden.
Genau. Und ich besitze einige nicht leere Adressen.
Eine häufigere Nutzung von Bitcoin kann zu mehr nicht-leeren Adressen führen, ohne das sich die Anzahl der Nutzer:innen verändert hätte.
Günter, der sich noch nie mit UTXO-Management beschäftigt hat und monatlich seine 100.000 sats aufs Hardwarewallet schiebrmt sorgt jedenfallsnicht für mehr Nutzer:innen. Allein hier braucht es eine gut begründete Abschätzung ubd entsprechende Fehlerrechnung.
Du bist hier ein bisschen kleinlich. Die Adressen sind eine Näherung, ein Proxy. Ich vermute, dass die mittlere Anzahl der nicht-leeren Adressen pro Benutzer mit der Zeit nicht wirklich wächst, dazu tragen auch UTXO-Konsolidierungen bei. Wenn das stimmt, dann ist die Näherung ok. Ein konstanter Faktor spielt keine Rolle.
Aber ja, ich verstehe, dass das Modell (wie vermutlich jedes andere auch) auf breite Ablehnung stößt. Kein Problem, aber ich halte es für besser als die gängige Konkurrenz (S2F etc). Insbesondere der durch das PL implizierte Support (ca. 1/2 des PL-Wertes) hat sich als sehr robust erwiesen. Sollte dieser nachhaltig brechen, würde mir das zu denken geben.
danke für Deine ausführliche Antwort. Ich denke, was Modelle angeht, ihre Erstellung, Evaluation, etc. haben wir dasselbe Verständnis. Sie sind halt essentiell in der Naturwissenschaft.
Ich verstehe Deinen Einwand, das das Modell simpel ist. Bitte denke daran, dass die Finanzmathematik sich ebenfalls der Mathematik/Physik bedient, damit Erfolge erzielt, aber trotzdem weit weg von perfekt ist. Wie gesagt, habe ich gar nicht den Anspruch, dass das BPL perfekt zu sein hätte. Nach meinem Verständnis ist das BPL einfach das beste, was wir bisher haben. Oder kennst Du bessere Modelle? Dann würde ich wahrscheinlich sofort wechseln
Ja, so verstehe ich es auch. Zum besseren Verständnis möchte ich einmal respektvoll provozieren:
Schwingungsgleichungen würde ich auf eine ähnliche Stufe wie das BPL stellen (mal davon abgesehen, dass es beim BPL nicht um schwingende Kurse geht). Beide rechnen mit einfachen Formeln und trotzdem sind sie von Nutzen.
Das hat auch gar keiner behauptet. Es ist aber gut, dies für die Mitleser zu erwähnen, nicht dass ihre Erwartungen an das BPL über das vertretbare Maß hinausschießen.
Das finde ich wieder zu hart. Denn Romane wollen nichts vorhersagen und haben daher weniger Vorhersagekraft als das BPL für den Worst Case.
Bei diesem Argument würde mich interessieren, wie Du das mit der Stabilität des BPL zusammenbringst. Die Kurvenparameter mussten seit 2019 nicht verändert werden. Sie scheinen also stabil zu sein. Spricht das nicht im finanzmathematischen Sinne für das Modell?
Das verstehe ich nicht. Das Modell wird doch täglich anhand der realen Kursdaten überprüft. Solange der Bitcoinkurs nicht unter den Worst Case Kurs fällt, den das BPL erwarten lässt, hat es genau dafür weiter seine Berechtigung. Oder nicht?
Und ja, Annahmen können Modell nicht prüfen. Auch in der Physik nicht. Ihr könnt nur überprüfen, ob die Annahmen, die ihr in Eure Modelle steckt, die Realität widerspiegeln. Ist das der Fall, vertraut ihr den Annahmen ein Stück mehr.
Das sind psychologische Experimente (zumindest die mit naturwissenschaftlichem Backround). Teilchenphysik stelle ich mir übrigens ähnlich vor.
Gilt das für Schwingungsgleichungen nicht genauso? Sie beleuchten nur einen ganz kleinen Teil der Physik und können nichts über die Halbwertszeit von Teilchen oder Lichtbrechung aussagen, weil sie dafür nicht gedacht sind.
Dafür ist das Modell nach meinem Verständnis nicht gedacht. Dafür ist die Varianz einfach zu groß, wie Du auch selbst schon zu recht angemerkt hast. Der Haupterkenntnisgewinn aus dem BPL ist die Preisschwelle, die Bitcoin nie mehr unterschreiten wird.
Korrekt. Das meinte ich mit dem Glück der Physiker. Eine grundlegende Veränderung der Welt ist eben äußerst unwahrscheinlich. Deswegen heißen Naturkonstanten auch Naturkonstanten. In der Psychologie ist es schon deutlich schwieriger derartige Eckpfeiler zu finden. Doch nur wer sie sucht, kann sie finden. Nur wer seine Annahmen experimentell auf die Probe stellt und immer zum selben Ergebnis kommt, kann ihnen vertrauen.
Klar, das denke ich schon lange verstanden zu haben. Ich denke auch, dass ihr lieben Physiker zu hohe Erwartungen an das BPL stellt. Ich bin da begnügsamer.
Für mich ist das BPL (aus Mangel an besseren Tools) das derzeit beste Modell, um die unterste Preisschwelle des Bitcoinkurses in die Zukunft zu schätzen. Und je länger es trägt, desto mehr bin ich bereit mich darauf zu verlassen. Natürlich wird das noch Jahre benötigen.
Ich sehe das PBL ein bisschen wie die Fouiertransformation und andere mathematische Werkzeuge, die sich die Finanzindustrie im Aktienmarkt zu nutze macht (davon abgesehen das das BPL ein Baby im Vergleich zur FT ist). In Kombination miteinander erhöhen sie die Wahrscheinlichkeit, den Markt richtig einzuschätzen. Eine Garantie bieten sie nicht, aber es reicht aus, um mit dem Werkzeugkasten Geld zu verdienen.
Darüber denke ich auch immer wieder nach. Da mir jedoch die Praxis fehlt, komme ich damit nicht wirklich weiter, als folgende Annahme zu treffen:
Das BPL ist das Konservativste aller Bitcoin Kursprognosemodelle, die so kursieren. Das S-Kurven Modell, Stock2Flow, Stock2Fomo, etc sind alle deutlich bullisher. Sollten sie recht behalten, freut mich das. Doch „planen“ tue ich aktuell lieber mit dem Worst Case des BPL.
Meinst Du damit, dass sich die Kurvenparameter von Zyklus zu Zyklus ändern? Falls ja, widerspräche das nicht der Skaleninvarianz des BPL? Wie gesagt, Statistik ist bei mir schon ewig her.
Was die Störeffekt angeht: Wenn das Modell robust ist, toleriert es Störeffekte. Weil menschliches Verhalten mega komplex ist, wird in der Psychologie angenommen, dass die Fehler gleichbleiben oder sich gegenseitig im Zaum halten. Und solange das Modell nicht daran scheitert, ist es doch ein Anfang, um einen Schritt weiterzugehen und mögliche Einflussfaktoren mit besseren Methoden und mit anspruchsvolleren statistischen Verfahren zu untersuchen.
Die Schwingungsgleichung ist falsifizierbar. Deswegen habe ich Vertrauen in sie. Ich konnte sie mehrfach überprüfen.
Ein willkürlicher Fit natürlich nicht. Der bricht eben, wenn er bricht. Heißt andersherum, er liefert mir keinen Erkenntnisgewinn.
Etwas anderes wäre es beispielsweise, wenn Du eine feste Population zu ihrer Nutzung von Bitcoin über 15 Jahre jährlich befragen würdest, um die Adaption nicht nur durch ein willkürliches t^x zu modellieren, sondern eben tatsächlich Informationen aus der Umwelt genommen hättest. Dann hättest Du wirkliche Indizien zu der Adaption. Genauso müsste das Modell die Geldmenge berücksichtigen, ggfs. Strompreise etc.
Aber das schöne ist ja, dass man sich solche Modelle für sich machen kann. Dann muss man auch nicht blind einem BPL folgen.
Du hast an der Stelle einen grundlegenden Denkfehler, der vielleicht auch die Ursache für unsere komplett unterschiedlichen Sichtweisen ist.
Die Schwingungsgleichung wird in ihrem Gültigkeitsbereich niemals falsifiziert werden, solange sich die Naturgesetze nicht ändern.
In der Physik wird der Gültigkeitsbereich bzw. die Genauigkeit der aktuell besten Theorie immer größer. Entweder durch Erweiterungen von Modellen oder durch komplett neue. Im bisherigen Gültigkeitsbereich bleibt das aktuelle Modell aber auch weiterhin immer gültig, wenn man mit der bisherigen Genauigkeit zufrieden war.
Das BPL wird aber irgendwann „brechen“. Es ist ab diesem Zeitpunkt einfach falsch und nichts mehr wert. Genauer gesagt ist es kein fester Zeitpunkt. Die Abweichung wird einfach irgendwann immer schlechter.
Bis dahin kannst du diese einfache Regression ja als Richtschnur verwenden. Aber daran ist einfach nichts besonders.
Jemand sieht, wie auch viele andere, dass der Kurs im doppelt logarithmischen Chart bisher grob einer Gerade folgt. Jetzt kommt er auf die geniale Idee, diese Gerade einfach zu extrapolieren und muss seine offensichtliche Erkenntnis überall kundtun. Deshalb schrieb ich oben „Wichtigtuer“.
Daran ist nichts besser oder genialer, als wenn ich im einfach logarithmischen Chart einen „Regenbogen“ extrapoliere. Beides kann ich als Anhaltspunkt verwenden.
Das Bitcoinfraktal wächst in die Entropietasche des Währungsraums.
Der realistischste Kursverlauf ist mMn. Stock2FOMO, Stock2FOMO zeichnet sich durch eine flachere Übergangszeit aus und einer hyperbolischen Hyperinflation am Ende
Man kann natürlich alles banalisieren, aber am Ende des Tages ist das ein guter Kennwert gewesen und wer anhand dessen investiert hat ist sehr zufrieden.
Also das ist schon eine Leistung, so ist es nicht.
Schwingungen sind fundamental anders weil diese um einen Potentialminimum herum schwanken. Das Potentialminimum bestimmt also immer den „Ort“ der Schwingung und die Störquellen die Ablenkung:
Wenn du dir also eine Potentialkurve vorstellst, dann kann diese an verschiedenen Stellen ein Minimum haben. Leichte Störungen von außen bewirken dann eine Schwingung um dieses Potentialminimum weil das Potential immer eine Kraft zurück zu diesem Minimum verursacht. Man kann sich das auch so vorstellen, das ein Objekt im Potentialminimum seine geringstmögliche Energie hat. Gibt man dem Objekt Energie hinzu, dann verliert es über die Zeit seien Energie wieder und findet zurück zum Grundzustand.
Erst eine Störung, die groß genug ist die Potentialwand zu überwinden bewirkt, dass die Objekte sich komplett anders verhalten. Was also große Störungen oder kleine Störungen sind bezieht sich also immer relativ zur Potentialwand.
Schwingungen sind insgesamt grundsätzlich eine Hilfe für die Betrachtung der Modelle weil jede Schwingung den Einfluss von kleinen Störungen negiert. Für Modelle ist das absolut praktisch weil du dann über die Schwingung mitteln kannst und somit das Potentialminimum relativ gut bestimmen kannst, ein „Ort“ (gerne auch Virtuell bezogen auf nichtphysische Größen wie Zeit, Energie, Geschwindigkeit oder andere transformierte Werte). Oder anders gesagt: Eine Schwingung bedeutet, dass du ein Potentialminimum vorliegen hast, ein Atraktor wo sich die betrachteten Objekte sammeln und über diesen du in einem Modell also eine hohe Aussagekraft machen kannst.
Solche Schwingungen findet man in dem betrachtetem Modell nicht, es gibt keine Attraktoren sondern nur eine monoton wachsende Kurve. Das ist kein Beinbruch aber eben auch kein Vorteil für das Modell und seine Aussagekraft.
Wenn du für dich denkst dass es das beste Modell ist, dann klar, benutze es. Aber dir sollte eben klar sein, dass es nur eines von beliebig vielen Modellen ist, die alle mehr oder weniger die gleiche Aussagekraft haben. Einige Modelle brechen eben früher, andere später und keiner kann dir sagen, welche jetzt genau besser oder schlechter sind, nur die Zeit wird es zeigen. Deswegen spare ich mir die Zeit irgendwelche mathematischen Berechnungen dazu anzustellen. Für mich reicht es aus, wenn ich die Kurve sehe und Pie*Dauemen eine Kurve da weitermale: den Trend. Für jegliche Vorhersagen bin ich damit genauso gut wie jedes mathematische Modell, habe aber viel Zeit und Energie gespart mir die Werte bis aufs letzte Komma auszurechnen. Werte, deren Genauigkeit das Modell zwar liefert, aber die schon beim einfachen Hinsehen im Fehlerbereich untergehen.
Viel viel wichtiger als die Berechnung der Trendlinie ist es, die Störfaktoren für den Trend abschätzen zu können, also sowas wie: Wird Bitcoin irgendwo verboten? Wird Bitcoin irgendwo adoptiert? Welche weiteren Faktoren könnten einen Einfluss auf den Bitcoinpreis haben?
Wenn du dir darüber Gedanken machst, dann kannst du den Preisverlauf besser schätzen als es dir diese mathematische Trendlinie jemals geben kann. Das folgt einfach daraus, dass die Aussagekraft des Modells nicht gegeben ist. Man sollte diese Modelle also nicht überbewerten sondern seine eigene Erfahrung und Informationen mit einfließen lassen.
Ich glaube hier wirst du emotional und verteidigst das Modell mehr als es verdient hat. Denn ich habe ja erklärt, dass das betrachtete Modell nichts vorhersagen kann, was du nicht vorher schon in das Modell hineingesteckt hast. Das Modell sagt lediglich aus: Wenn das so weiter geht, dann geht es so weiter. Welche Vorhersage steckt da wirklich drin? Woher weißt du bzw. welche Sicherheit hast du, dass es so weiter geht und nicht anders? Das meine ich mit die Vorhersagekraft des Modells ist nicht gegeben.
Genauso kannst du den Roman verstehen: Wenn die Realität der Protagonisten im Roman so ist, wie das Buch es beschriebt, dann handeln die Personen so, wie im Buch beschrieben.
Das kann interessant sein, muss aber nichts mit der Realität zu tun haben, in der wir leben. Genauso wie es viele Romane mit vielen Realitäten gibt, so gibt es beliebig viele Vorhersagen oder Modelle für den Bitcoinpreis. Alle diese hypothetischen Modelle können richtig sein bis sie widerlegt werden.
Romane haben den fundamentalen Informationsvorteil, dass wir wissen, dass sie fiktiv sind, also ausgedacht und nur angelehnt an die Realität, aber eben nicht geau die Realität sind. Die Modelle suggerieren aber die Realität abbilden zu wollen, was sie nunmal nicht tun. Sie bilden nur die aufgezeichnete Vergangenheit ab, wie ein Roman. Die Vergangenheit ist fest, aber aus diesem Trend die Zukunft vorherzusagen ist immernoch reine Fixion. Deswegen habe ich den Vergleich gebracht.
Ja, dann mal ein einfaches Beispiel: Sagen wir du hast ein Stausee, der mit einem Füllstand von 100 Metern gefüllt ist. Jetzt misst du jede Minute den Füllstand und trägst ihn in eine Tabelle ein. Mit ein wenig Wind und Wellen bekommst du leicht schwankende Werte. Aber du kannst diese Werte mit einer Ausgleichskurve versehen und somit eine Gerade durch die Punktwolke ziehen und wirst wahrscheinlich auf Werte nahe der (hier im Roman des Stausees definierten) exakten 100 Meter kommen.
Damit hast du ein neues Modell aufgestellt, dass mein ausgedachtes Beispiel (Roman) versucht zu analysieren und mit der Gerade kannst du jetzt auch den Füllstand in 20 Jahren berechnen. Aber eben nur, wenn sich an der Gesamtsituation nichts ändert. Klar wird dein Modell jede Minute mit neuen Messwerte bestätigt. Kannst du dir dann mit jedem Messwert immer sicherer sein, dass in 20 Jahren immernoch dieser Füllstand ununterbrochen auf 100 Meter steht?
Wenn in 5 Jahren eine Dürre kommt und der Stausee abgelassen wird, dann ist das ein Ereignis, eine Störung von außen, das dein Modell bricht. Also egal wie sicher du dir mit deinen aufgenommenen Werten aus der Vergangenheit warst, diese Störung ist so groß, dass dein Modell einfach falsch wird weil die Realität von deinem Modell abweicht. Genauso hätte es eine Flut geben können um die Werte unerwartet ansteigen zu lassen oder der Staudamm bricht und senkt deinen Wert wieder unerwartet. All diese Ereignisse stecken nicht in dem Modell und werden nicht berücksichtigt. In deinem Modell stecken vielleicht die kleinen Schwankungen der Wasserwellen, nicht aber die großen Störungen, die zufällig auf den Wasserstandswert einwirken können.
In einer isolierten Labormessung oder ausgedachten Situationen kannst du dein Modell als immerwährend richtig darstellen, die Realität ist aber kein isoliertes Labor. Genau das meine ich: Klar kannst du dich Tag für Tag sicherer sein, dass der aktuelle Trend für den Bitcoinpreis mit diesem Modell korrekt vorausgesagt wird, aber du kannst dich nie sicher sein, dass die Bedingung für den Trend sich nicht ändert und somit das Modell sofort seine Vorhersagekraft verliert.
Und weil das Modell zu einfach ist um solche externen Störungen vorherzusagen, was ja auch zugegebenermaßen in der komplexen Welt quasi unmöglich ist, ist es ein nicht verlässliches Modell. Wie gesagt, den einfachen Trend kann ich dir auch per Hand malen, da brauche ich keine Regression dafür.
Das ist ein interessanter Punkt. Hier kommen wir nämlich zu rekursiven Modellen. Du kannst dir ja jedes Modell wie eine Blackbox vorstellen mit Eingang und Ausgang. Die Betrachtung verlagert sich dann aus dem Modell auf eine höhere Abstraktionsebene, also wie verschiedene Modelle oder Blackboxen miteinander verknüpft sind oder miteinander interagieren. Auch das „herausgezoomte“ Modell mit kleinen Blackboxen drinnen ist wieder ein eigenständiges Modell.
Man kann also je nachdem was man untersucht oder betrachtet, Modelle einfach als Blackbox benutzen und sich darauf verlassen, dass deren Ausgabewerte „stimmen“ um so im Zusammenspiel mit anderen Modellen die Funktionsweise eines größeren Modells überprüfen oder man kann in die jeweiligen Modelle hineinzoomen um zu schauen, wie diese Modelle im inneren Funktionieren und welche Blackboxen oder Objekte da so Werkeln um als Gesamtsystem zu funktionieren. Da das aber beliebig komplex werden kann muss man sich in der Betrachtung auf etwas fokussieren. Alles was darüber hinaus zu komplex wird oder im kleinen zu viele Objekte werden muss in Blackboxen verpackt bzw. vereinfacht werden.
Im Endeffekt gilt bei diesem Sammelsorium an Modellen=Balckboxen=Objekten immer das evolutionäre Prinzip: Die Modelle mit der besten Vorhersagekraft gegenüber dem Ressourcenverbrauch (Energie, Zeit) zur Berechnung bzw. Durchdenkung und der benötigten Genauigkeit liefern die besten Ergebnisse und bilden die Realität somit am besten ab. Und wer die Realität am besten einschätzen kann, der bekommt eben auch evolutionäre Vorteile für sein leben (und kann diese Vorteile auch seinen Kindern oder anderen Objekten weitergeben).
Der Energieverbrauch für die Modelle ist extrem wichtig. Wir Menschen benötigen keine komplexen Bewegungsgleichungen um im Alltag durch die Welt zu laufen. Es reicht, wenn wir die benötigte Kraft für die Beine abschätzen. Das kann zu Fehlern führen, ist im allgemeinen aber effektiver weil es Energie spart als jeden Schritt bis ins kleinste zu berechnen wie die anfänglichen Roboter ohne KI.
Klar ist es gut, wenn wir es berechnen können und die Mathematik dahinter verstehen, aber es ist eben nicht sinnvoll, das überall so anzuwenden, nur weil es geht. Wir müssen immer abschätzen, wie Anstrengend ein Ergebnis gegenüber einer Näherung ist, also wie genau wir das Ergebnis wirklich benötigen.
Wie sicher bist du dir bei dieser Aussage? Denn Qualitativ unterscheidet sich deine Aussage nicht von meiner. Klar kann ich sagen, dass der Bitcoinpreis nie wieder unter 1€ fallen wird und mit allem was wir wissen ist das eine Aussage, die sehr wahrscheinlich ist. umso größer ich diesen Wert aber ansetze, desto wahrscheinlicher wird es auch, dass ich unrecht haben werde. Was meinst du: Wird der Bitcoinpreis nochmal unter 100€ fallen? oder unter 100000€? Aber auch wenn du damit im Gefühl hast, dass die Wahrscheinlichkeit abnimmt, wie groß nimmt die Wahrscheinlichkeit dann genau ab?
Das beschriebene Modell gibt dir durch die Regressionskurve für jede Zeit eine Zahl vor, weil es eine analytische Funktion ist. Aber es gibt dir keine Wahrscheinlichkeit dafür, wie gut diese Zahl wirklich ist.
und genau das versuche ich ja die ganze Zeit zu erklären: Wenn du die Kurve nicht als Preiskurve interpretierst sondern als Preisschranke, dann kannst du über die Höhe der analytischen Kurve auch die Wahrscheinlichkeit einstellen, wie gut dein Modell ist. Du kannst die analytische Funktion ja mit den Regressionsparametern beliebig wählen. Wenn du das Modell also so wählst, dass kleinere Werte hinten raus kommen, dann steigt die Wahrscheinlichkeit, dass richtige Aussagen hinten rauskommen. Wenn du z.B. extrem rangehst und sagst, das Modell spuckt immer nur 42€ aus, dann kannst du dir zwar zu 100% sicher sein, dass die Aussage Bitcoinkurs > 42€ für immer richtig ist, aber diese Aussage bringt dir nicht viel wenn der Kurs um Größenordnungen größer ist. Man könnte auch sagen, das ist intuitiv klar.
Umso größere Werte aber aus der Funktion kommen, desto wahrscheinlicher ist diese Aussage auch mal falsch. Spuckt die Funktion z.B.für heute 90000€ aus, dann würde ich mir nichtmal 40% Chance einräumen, dass die Aussage Bitcoinkurs > 90000€ für alle zukünftigen Kurse gilt. Das Modell kann dann Glück haben oder es gilt irgendwann als gescheitert.
Die Aussage: Wird nie wieder unterschreiten ist dann zwar ohne Fehlerbalken eine 100%tige Aussage aus dem Modell, aber die Gesamtwahrscheinlichkeit zusammen mit der Eingangsbedingung ist trotzdem nicht 100% sondern kleiner. Das ist genau die Aussage: Das Modell suggeriert eine größere Sicherheit als es liefern kann.
Und hat damit die größte Wahrscheinlichkeit nicht falsch zu sein aber gleichzeitig die geringste Aussagekraft bezüglich des Preises. Es ist sozusagen schwammig genug um immer richtig zu sein.
Kleine Störeffekte sind in den gefitteten Parametern „gespeichert“ bzw. gehen in dem Sicherheitsbereich unter, das es kleinere Werte für die Zukunft liefert als nötig. Große Störeffekte kann das Modell nicht berücksichtigen, dafür ist es zu einfach gestrickt.
PS: Danke an @HODLer und @skyrmion , ich habe einige Dopplungen weil ich erst auch Achse reagiert habe und dann weitergelesen habe