Grundlegend verstehe ich das Mining schon(korrigiert mich wenn ich falsch liege)
Ein Miner probiert verschiedene Zahlenkombination aus bis er die Lösung gefunden hat umso mehr TH der Miner hat umso mehr kombinationen schafft er in der Sekunde. Umso mehr Miner im Netzwerk sind Steigt die Difficulty indem die Zahlenreihenfolge länger wird. Hoffe ich liege bis jetzt soweit richtig.
Jetzt zu meiner Frage:
Woher weiß der Miner was die „Lösung“ ist?
Ich weiß das die Lösung wiederum alle Miner kontrollieren.
Aber wie entsteht die Lösung? Sind mehrere Lösungen Richtig?
Danke für die Erklärung soweit habe ich das verstanden und ist auch klar auch das mit der Schwierigkeit…….
So wie ich das dann verstehe ist die Aufgabe bei jedem Block die selbe? Wie in deinem Beispiel Würfel eine Zahl die niedriger ist wie XY je nach difficulty schwieriger oder leichter……
Liege ich hier soweit richtig?
Wenn aber die Aufgabe ja immer die selbe ist müsste die Antwort ja auch immer die selbe sein und man könnte ja dann Tricksen oder?
In deinem Beispiel einfach zwei Würfel nehmen wo nur 1 drauf ist und man gewinnt jedesmal……
Prinzipiell sind mehrere Lösungen Richtig, die dann aber in unterschiedlichen Blöcken resultieren. Die gleichen Eingangsparameter hingegen erzeugen immer den gleichen Block-Hash. Deshalb kann man da auch nicht tricksen. Der Block-Hash wird dann von allen Full Nodes (nicht nur anderen Minern) validiert.
Zu den Eingangsparametern gehören die Transaktionen, ein Zeitstempel, eine Nonce, die Coinbase Transaktion und der Hash des vorangegangenen Blocks. Beim Minen werden diese Parameter (bis auf den vorangegangenen Block) angepasst, in der Hoffnung, dass der daraus resultierende Hash der geforderten Difficulty genügt. Das definiert dann auch die Lösung – ein Hash, welcher der geforderten Difficulty genügt.
Ja um ehrlich zu sein raucht mein Kopf und ich verstehe das Grundprinzip schon
Für mich ich die „Frage“ und „Antwort“ Geschichte leider noch nicht schlüssig
Das mit den Würfeln war schon eine coole Erklärung die hat mich schon weiter gebracht nur das gedanklich umzusetzen für die Hash und Blöcke usw fehlt mir noch
Sorry aber euch vielen vielen Dank für die Antworten……
Als erstes ist es wichtig zu verstehen, was eine Hashfunktion macht. Die Hasfunktion nimmt eine beliebige Bitfolge aus Nullen und Einsen und verwandelt diese in eine andere Bitfolge.
Dabei gelten (unter anderem) folgende wichtige Regeln:
Es gibt kein Zufall. Die gleiche Bitfolge wird immer zum gleichen Ergebnis führen. zB. „aaa“->53637 „bbb“->19475 und „aaa“->53637 (Die bei Bitcoin verwendete Funktion ist etwas komplexer, aber als Beispiel reichen diese Zahlen) Die Ergebnisse sehen zwar zufällig aus, sind aber aus dem Startwert berechenbar.
Die Funktion ist nicht umkehrbar. aus dem Hashwert 53637 kannst du das „aaa“ nicht mehr eindeutig berechnen. Es ist also eine Einwegfunktion.
Nun kann ein Miner aus einem anderem Block einen gültigen Nachfolger bestimmen indem er einen Block erstellt, deren Hash kleiner als die Difficulty ist. In dem Hash fließen einige wichtige Statuswerter (der Header des Blockes) ein. Unter anderen Parametern sind das:
der Vorgänger des potenziell neuem Blockes. Wichtig damit man die Referenz in der Block-Kette kennt
der Merkletree, also die Referenz auf die gesammten Transaktionen des Blockes
eine zufällige Zahl, die der Miner frei variieren kann
Der Miner Baut also den Block zusammen, hasht den Header und schaut ob das Ergebnis kleiner als die Difficulty ist. zB:
„block31415,transaktionen7376,zufall1“->1458945
„block31415,transaktionen7376,zufall1“->1458945
„block31415,transaktionen7376,zufall2“->6920156
„block31415,transaktionen7376,zufall3“->9740320
„block31415,transaktionen7376,zufall4“->0038501 wir haben einen Block gefunden
Das wiederholt der Miner solange bis er einen Block gefunden hat. Da die Hashfunktion bei gleichem Input auch das gleiche Ergebnis ausspuckt muss er den Zuffalswert jedesmal ändern um einen anderen Hash zu generieren. Und das ist das Würfeln beim Minen. Jede Zahl kann das Ergebnis sein, die Chance ist halt nur recht klein. Hat er einen Block gefunden, veröffentlicht er ihn einfach. Jeder Nodebesitzer kann mit einer einfachen schnellen Hashfunktion das Ergebnis überprüfen. Der Miner musste aber x-fach neue Blöcke Generieren bis er endlich einen Block gefunden hat, deren Hash kleiner als ein bestimmter Wert ist.
Das Beispiel ist natürlich etwas vereinfacht da der Header noch mehr Informationen beinhaltet und anders Formatiert ist aber das Prinzip bleibt gleich bei Bitcoin. Auch die Hashfunktion spuckt eine deutlich größere Zahl aus als im Beispiel.
Generell ist das Minen mit Lotto zu vergleichen. Mit dem erstellen eines Blockes kaufst du dir mit Energie ein Los. Um zu schauen ob dein Los gewonnen hat hashst du den erstellten Block (rubbelst das los frei) und wenn du gewonnen hast holst du dir die Belohnung ab. In den meisten anderen Fällen verwirfst den Block einfach und erstellst einen neuen.
Vielleicht als kleine fortgeschrittene Ergänzung:
Der Zufallswert des Blockes ist lediglich 4 Bytes groß. Heutige Miner können diesen binnen einer Sekunde komplett durchsuchen und meist keinen Treffer finden. Trotsdem muss der Header variiert werden, andernfalls könnte man meinen dass es unmöglich ist einen Treffer zu finden.
Heutzutage wird der Header nicht mehr nur in dem Zufallswert verändert, sondern auch in der Blockzeit oder durch umsortieren der Transaktionen was den Merkle-Tree hash im header ändert.
Hey super vielen Dank für die Erklärung sehr gut vielen Dank…….
Allerdings hätte ich da noch eine kleine Frage:sweat_smile:
Du schreibst (wenn ich es richtig verstanden habe) der gefundene Block muss kleiner der Difficulty sein klingt einleuchtend und entspricht ja auch dem Würfel Prinzip……
Wenn der miner jetzt einen gefunden hat kennst er ja den Hash die Zufallzahl und könnte doch beim nächsten mal einfach den selben Hash Zufallszahlen benutzen da die difficulty sich ja erst nach 2024 Blöcken oder so ändert und er könnte immer weiter den Hash nutzen……
Oder gilt als „Aufgabe“ das auch niemals der gleiche Hash verwendet werden darf?
Hoffe ich versteht was ich sagen will:sweat_smile:
Der Hash ist nur die Ausgabe, das Ergebnis, der Hashfunktion.
Eingabe ist der Blockheader, und der ist logischerweise automatisch bei jedem Block ein anderer. Man kann den alten Input also nicht nachkonstruieren.
Man nennt eine Eigenschaft von (kryptographischen) Hashfunktionen auch den Lawineneffekt. Soll heissen dass bereits kleinste Änderungen am Input zu einem komplett anderen, nicht nachvollziehbaren Hashwert führen. Deswegen kann man sich nicht an alten Ergebnissen orientieren, sondern bei jeder Berechnung ist es ein Wahrscheinlichkeitsspiel wie beim Werfen eines Würfels.
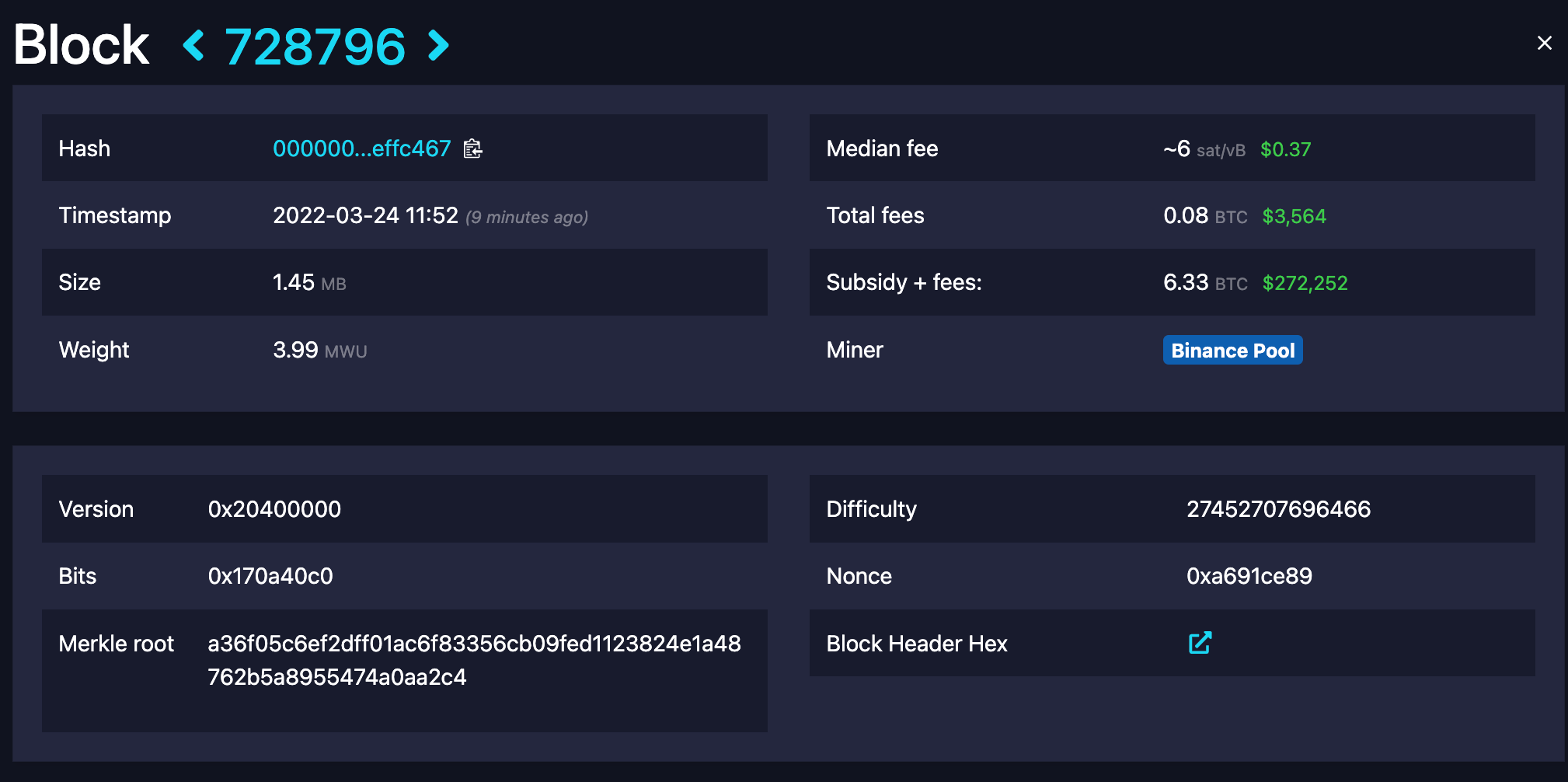
Da stehen Informationen wie der Zeitstempel, die Schwierigkeit, ein Fingerabdruck aller Transaktionen, eine Nonce, eine Versionsnummer und der Hash des vorherigen Blocks. Damit identifizieren wir einen Block, wie Empfänger, Absender und Betreff einer E-Mail.
Hier stehen jetzt ein paar mehr Informationen die nur hier vom Block Explorer gezeigt werden:
Es wird eben nur dieser Header gehasht und nicht der komplette Block. Trotzdem hat (durch den Fingerabdruck der Transaktionen) jede kleinste Änderung direkten Einfluss auf den Header und damit auf den Hash.